
상명대학교 / 서광규 교수
*이 원고는 국제표준문서인 “ITU-T Y.3531 (2020) Cloud computing ? Functional requirements for machine learning as a service”를 토대로 작성되었음
3. MLaaS의 기능적 요구 사항
3-1. ML 데이터 수집 및 저장 요구 사항
[ITU-T Y.3600 Big data ? Cloud computing based requirements and capabilities]은 빅데이터 측면에서 데이터 수집 및 저장 기능 요구 사항을 제공한다. MLaaS의 기능에는 데이터 수집 및 저장도 포함되며 이러한 ML 활동의 여러 기능적 요구 사항은 [ITU-T Y.3600 Big data ? Cloud computing based requirements and capabilities]에 지정된 빅 데이터의 요구 사항과 다르지 않다.
CSP:BDIP에서 CSP:MLSP로, CSN:DP에서 CSN:MLDP로 역할을 빅데이터에서 ML로 변경하여 [ITU-T Y.3600 Big data ? Cloud computing based requirements and capabilities]에 명시된 빅데이터에 대한 기능 요구사항을 다음과 같은 기능 요구사항으로 상속한다.
데이터 수집 및 저장 요구 사항은 다음과 같다.
1) CSP:MLSP는 여러 CSN:MLDP에서 병렬로 데이터 수집을 지원해야 한다.
2) CSN:MLDP는 메타데이터 게시를 통해 CSP:MLSP에 데이터를 노출하는 것이 좋다.
3) CSP:MLSP는 다양한 모드의 다양한 CSN:MLDP에서 데이터 수집을 지원하는 것이 좋다.
※ 참고 1 - 데이터는 CSP:MLSP에 의해 데이터 수집 프로세스가 시작되는 풀 모드 또는 CSN:MLDP에 의해 데이터 수집 프로세스가 시작되는 푸시 모드와 같은 다양한 모드에서 수집될 수 있다.
4) 접근 가능한 데이터 검색을 위해 CSN:MLDP가 CSP:MLSP에 중개 서비스를 제공하는 것이 좋다.
※ 참고 2 ? 중개업체는 데이터 사양, 데이터 지침, 전자 액세스 방법, 라이센스 정책 및 데이터 품질과 같은 데이터 정보가 있는 데이터 카탈로그를 제공한다.
5) CSP:MLSP는 충분한 저장 공간, 탄력적인 저장 용량 및 효율적인 제어 방법으로 다양한 데이터 유형을 지원해야 한다.
6) CSP:MLSP는 다양한 데이터 형식과 데이터 모델에 대한 스토리지를 지원해야 한다.
※ 참고 3 - 데이터 형식에는 텍스트, 스프레드시트, 비디오, 오디오, 이미지 및 지도가 포함된다. 데이터 모델에는 관계형 모델, 문서 모델, 키-값 모델 및 그래프 모델이 포함된다.
3-2. ML 데이터 라벨링 요구사항
ML 데이터 라벨링 요구사항은 다음과 같다.
1) CSP:MLSP는 CSN:MLMD에 대한 라벨링 작업을 위한 도구를 제공해야 한다.
※ 참고 1 ? 라벨링 작업 도구는 이미지, 비디오, 텍스트와 같은 데이터 형식에 대해 다양한 유형의 태깅 단위를 제공한다.
2) CSP:MLSP는 레이블이 지정된 ML 데이터에 대한 감사 데이터를 제공해야 한다.
※ 참고 2 ? 라벨링에 대한 감사 데이터는 라벨링의 정확성 및 라벨링의 일관성과 같은 데이터 라벨링 품질을 향상시키는 데 활용된다.
※ 참고 3 ? 감사 데이터는 요청이 도착하거나 ML 모델 개발에 대한 라벨링 품질이 좋지 않을 때 피드백으로 CSN:MLDP에 보고된다.
3) CSN:MLDP는 데이터 라벨링 작업에 대한 정보를 제공해야 한다.
※ 참고 4 - 데이터 라벨링 작업에 대한 정보에는 데이터 유형, 라벨링 단위 및 라벨러의 합의된 다수가 포함된다.
3-3. ML 데이터 전처리 요구사항
다음 요구사항은 [ITU-T Y.3600 Big data ? Cloud computing based requirements and capabilities]의 빅데이터 기능 요구사항을 부분적으로 승계하여 CSP:BDIP에서 CSP:MLSP로 역할을 빅데이터에서 ML로 변경하여 도출한 것이다.
ML 데이터 사전 처리 요구 사항은 다음과 같다.
1) CSP:MLSP가 데이터 집계를 지원해야 한다.
2) CSP:MLSP는 다양한 형식으로 수집된 데이터의 통합을 지원하는 것이 좋다.
※ 참고 1 ? 데이터 통합은 예를 들어 웹 페이지, 사진, 비디오, SNS 데이터 및 통화 기록에서 추출된 사람, 위치 또는 날짜에 대한 데이터를 텍스트 형식으로 통합하는 데 사용된다.
3) CSP:MLSP는 비정형 데이터 또는 반정형 데이터에서 정형 데이터로의 데이터 추출을 지원하는 것이 좋다.
※ 참고 2 - 이 요구사항은 데이터 저장에도 적용될 수 있다.
4) CSP:MLSP는 학습, 검증 및 테스트를 위해 ML 데이터를 데이터 세트로 분할하기 위한 구성을 제공해야 한다.
※ 참고 3 ? 학습, 검증 및 테스트 데이터 세트는 완전히 독립적으로 구분된다.
3-4. ML 데이터 분석 및 기능 엔지니어링 요구 사항
CSP:BDIP에서 CSP:MLSP로 역할을 빅데이터에서 ML로 변경하여 도출한 [ITU-T Y.3600 Big data ? Cloud computing based requirements and capabilities]의 빅데이터 기능 요구사항을 상속하여 다음 요구사항을 따른다.
ML 데이터 분석 요구 사항은 다음과 같다.
1) CSP:MLSP는 다양한 데이터 유형과 형식에 대한 분석을 지원해야 한다.
2) CSP:MLSP는 연관성 분석을 지원해야 한다.
※ 참고 1 ? 연관성 분석은 데이터 간의 관계를 밝히는 작업이다.
3) CSP:MLSP는 다양한 데이터 분석 알고리즘을 지원해야 한다.
※ 참고 2 - 데이터 분석 알고리즘에는 분류, 클러스터링, 회귀, 연관 및 순위 지정에 대한 알고리즘이 포함된다.
4) CSP:MLSP는 ML 데이터의 관련 기능의 하위 집합을 결정하기 위해 기능 선택을 제공하는 것이 좋다.
5) CSP:MLSP는 ML 데이터의 기능 범위를 정규화하기 위해 기능 확장을 제공하는 것이 좋다.
6) CSP:MLSP는 ML 데이터의 원래 특징에서 새로운 개선된 특징을 생성하기 위해 특징 추출을 제공하는 것이 좋다.
3-5. ML 모델 학습 요구 사항
ML 모델 학습 요구 사항은 다음과 같다.
1) CSN:MLMD는 CSP:MLSP에 ML 모델 및 카탈로그의 레지스트리를 제공해야 한다.
2) CSP:MLSP는 ML 모델 사용에 대한 피드백을 CSP:MLMD에 제공하는 것이 좋다.
※ 참고 1 - 피드백에는 CSC:MLSU가 경험한 고성능의 응용 학습 작업이 포함된다. CSP:MLMD는 피드백을 사용하여 ML 모델을 업데이트한다.
3) CSP:MLSP는 하이퍼파라미터 값을 구성해야 한다.
4) CSN:MLMD가 기본 구성 하이퍼파라미터 값을 제공하는 것이 좋다.
5) CSN:MLMD는 하이퍼파라미터 조정을 위해 제한된 값 범위를 제공하는 것이 좋다.
※ 참고 2 - 제한된 범위의 값은 ML 모델에 채택 가능한 하이퍼파라미터 값이다.
6) CSP:MLSP는 학습 결과의 시각화를 제공하는 것이 좋다.
※ 참고 3 - 시각화의 예로는 학습 결과에 대한 분석 정보를 보여주는 차트, 표, 분포도 및 그래프가 있다.
7) CSP:MLSP는 ML 모델 학습 작업을 제공해야 한다.
※ 참고 4 ? ML 모델 학습 작업에는 ML 모델 학습 시작, 중지 및 재개가 포함된다.
8) CSP:MLSP는 검증 데이터세트와 함께 ML 모델 검증 프로세스를 제공해야 한다.
9) CSP:MLSP는 ML 모델 훈련 중에 학습 상태 모니터링을 제공하는 것이 좋다.
※ 참고 5 - 학습 상태에는 예상 학습 시간, 적용된 하이퍼파라미터 세트 및 메모리 사용량이 포함된다.
10) CSP:MLSP는 훈련된 ML 모델에 대한 성능 평가를 제공해야 한다.
11) CSP:MLSP는 하이퍼파라미터 세트가 적용된 학습된 ML 모델의 평가 결과를 저장해야 한다.
12) CSP:MLSP는 하이퍼파라미터 최적화 방법을 제공하는 것이 좋다.
※ 참고 6 - 하이퍼파라미터 최적화에는 ML 모델 학습을 위한 최적의 하이퍼파라미터 세트 선택이 포함된다. 하이퍼파라미터 최적화 방법의 예로는 그리드 검색, 베이지안 최적화 및 진화 최적화가 있다.
13) CSP:MLSP는 자동화된 ML 모델 검색 방법을 제공하는 것이 좋다.
※ 참고 7 ? 자동화된 ML 모델 검색은 목표 학습 작업의 성능을 높이기 위해 ML 모델의 설계를 찾다.
14) CSP:MLSP는 다른 ML 프레임워크에서 사용할 수 있도록 ML 모델 변환을 제공하는 것이 좋다.
15) CSP:MLSP는 분산 ML 모델 학습을 제공하는 것이 좋다.
※ 참고 8 ? 분산 ML 모델 학습은 결과 생성을 가속화하기 위해 여러 작업자 노드에서 ML 모델을 학습하는 것이다.
3-6. ML 모델 모니터링 요구 사항
ML 모델 모니터링 요구 사항에는 다음이 포함된다.
1) CSP:MLSP는 ML 모델 학습 중에 리소스 활용도 모니터링을 제공해야 한다.
※ 참고 1 ? 자원 활용에는 처리 장치(예: 중앙 처리 장치(CPU) 또는 그래픽 처리 장치(GPU)), 메모리, 저장 장치 및 네트워크 활용이 포함된다.
2) CSP:MLSP는 ML 모델 학습 중에 리소스 활용 과부하 경고를 발행하는 것이 좋다.
3) CSP:MLSP는 타임스탬프와 함께 리소스 활용 내역을 보고해야 한다.
4) CSP:MLSP는 학습 실패를 감지하거나 유망하지 않은 모델 성능을 측정하여 자동 중단 기능을 제공해야 한다.
※ 참고 2 - 학습 실패 감지에는 ML 매개변수 업데이트 실패가 포함된다.
5) CSP:MLSP는 자동 중단을 위한 임계값을 설정하는 것이 좋다.
※ 참고 3 ? 원치 않는 조기 결과를 피하기 위해 사용자 정의 임계값을 사용하여 자동 중지가 실행된다. 원하지 않는 결과에는 과도한 훈련과 성능 저하가 포함된다.
6) CSN:MLMD가 자동 중단을 위한 기본 임계값을 제공하는 것이 좋다.
7) CSP:MLSP는 ML 모델 훈련 중 학습 실패 이력을 저장해야 한다.
※ 참고 4 ? 이력에는 자원 활용, 성능 측정 및 자동 중지 실행에 대한 로그가 포함된다.
3-7. 훈련된 ML 모델 배포 및 재훈련 요구 사항
훈련된 ML 모델 배포 및 재훈련 요구 사항은 다음과 같다.
1) CSP:MLSP는 훈련된 ML 모델의 레지스트리를 제공해야 한다.
※ 참고 1 ? 훈련된 ML 모델은 적용된 입력/출력 데이터 및 ML 모델 구조를 포함하는 스키마에 등록된다.
2) CSP:MLSP는 학습된 ML 모델 메타데이터를 제공해야 한다.
※ 참고 2 ? 훈련된 ML 모델 메타데이터에는 평가된 성능과 적용된 하이퍼파라미터 세트가 포함된다.
3) CSP:MLSP는 대상 하드웨어 배포에 적용 가능한 형식으로 훈련된 ML 모델을 내보내야 한다.
4) CSP:MLSP는 배포된 ML 모델에 대한 성능 모니터링을 선택적으로 제공할 수 있다.
5) CSP:MLSP는 훈련된 ML 모델의 성능을 관리하기 위한 재훈련 정책을 제공해야 한다.
※ 참고 3 - 재훈련 정책에는 학습 매개변수 재설정, ML 모델 최적화를 위한 학습용 새 데이터 추가가 포함된다.
6) CSP:MLSP는 측정된 ML 모델 성능에 따라 ML 모델 재학습을 제공하는 것이 좋다.
4. MLaaS 유즈 케이스
유즈 케이스에서는 MLaaS 기능 운영 및 MLaaS의 관련 기능 요구 사항에 대한 예를 제공한다. 또한 MLaaS를 사용하여 ML 애플리케이션을 운영하는 시나리오와 MLaaS의 관련 기능 요구 사항을 제공한다.
4-1. ML 데이터 어노테이션 및 라벨링 관리
<유즈 케이스: ML 데이터 어노테이션 및 라벨링 관리>
| ?제목 | ML 데이터 어노테이션 및 라벨링 관리 |
| 설명 | 이 사용 사례에서는 데이터 할당, 주석 생성, 결과 보고 및 ML 데이터 병합을 포함하는 ML 데이터 관리 절차를 설명한다. 다음은 주석자를 사용하여 ML 데이터를 관리하기 위한 구체적인 단계이다. 1) CSP:MLSP는 ML 데이터 서버를 설정하고 CSN:DP에서 원시 데이터를 수집한다. 2) CSP:MLSP는 원시 데이터에 주석을 할당하도록 요청한다. 3) CSN:MLDP는 CSP:MLSP에서 제공하는 주석 방법을 사용하여 원시 데이터에 주석을 단다. 4) CSN:MLDP는 주석이 달린 데이터세트를 CSP:MLSP에 제공한다. 5) CSP:MLSP는 주석이 달린 데이터에 결정 정책을 적용한다. A. CSP:MLSP는 각 주석자의 주석이 달린 데이터에 대해 '수락' 또는 '거부'를 결정한다. B. CSP:MLSP는 주석이 달린 데이터의 품질 결과를 저장하거나 보고한다. C. CSP:MLSP는 허용된 데이터를 ML 데이터세트에 병합한다. |
| 역할/하위역할 | CSN:MLDP |
| 그림(선택) | 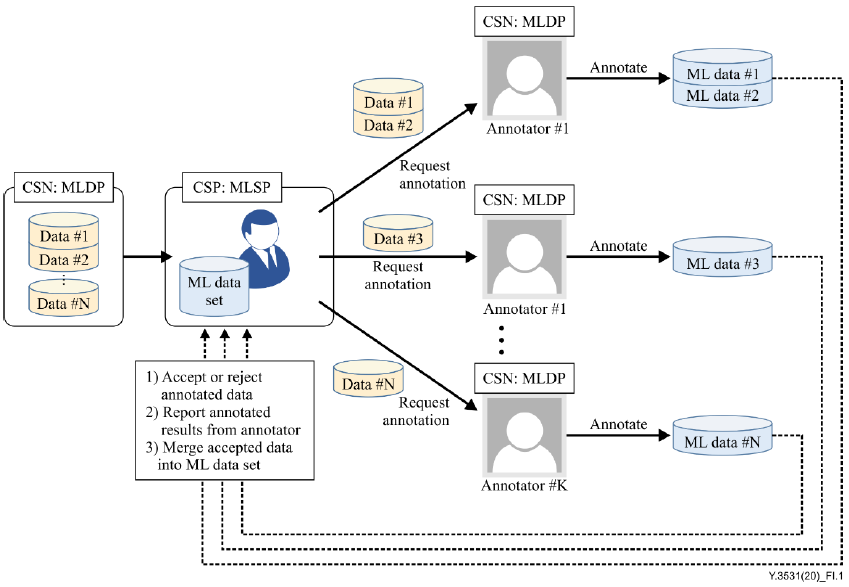 |
| 전제조건(선택) | CSN:MLDP는 ML 데이터 서버를 운영하여 주석자에게 데이터 리소스를 예약하거나 할당한다. CSN:MLDP는 CSN:DP에서 주석을 위한 원시 데이터를 검색하고 요청한다. |
| 사후조건(선택) | CSN:MLDP는 ML 결과 및 학습 진행 상황을 CSC:MLSU에 보고하기 위한 인터페이스를 제공한다. |
4-2. 사용자 구성을 사용한 모델 학습
<유즈 케이스: 사용자 구성을 사용한 모델 학습>
| ?제목 | 사용자 구성을 사용한 모델 학습 |
| 설명 | 이 사용 사례에서는 클라우드 컴퓨팅의 모델 훈련 절차를 설명한다. 훈련용 단일 머신은 기본 훈련으로 간주된다. 다음은 이 사용 사례의 모델 학습을 위한 일반적인 단계이다. 1) CSP:MLSP는 사용자와의 모델 훈련을 위한 인터페이스가 있는 기계 학습 엔진이 포함된 가상 머신을 설치한다. 2) CSN:MLMD는 ML 훈련을 위한 ML 모델을 CSP:MLSP에 제공한다. 3) CSN:MLMD는 ML 모델에 적합한 ML 데이터를 CSP:MLSP에 제공한다. ※ 참고 - ML 모델과 데이터 쌍을 준비하기 위해 CSC:MLSU는 ML 모델과 모델에 대한 적절한 ML 데이터를 요청하거나 CSP:MLSP는 ML 모델 쌍과 CSC:MLSU에 대한 ML 데이터를 제공한다. 이 준비 시나리오는 이 사용 사례의 범위를 벗어난다. 4) CSC:MLSU는 머신러닝 훈련을 위한 학습 정책과 매개변수를 구성하고 설정한다. 5) CSP:MLSP는 ML 모델을 훈련하고 CSC:MLSU에 보고하기 위해 훈련 결과의 성능을 추적한다. 6) CSP:MLSP는 훈련된 모델과 훈련 결과를 지정된 소스에 저장한다. |
| 역할/하위역할 | CSN:MLMD CSN:MLDP CSP:MLSP CSC:MLSU |
| 그림(선택) | 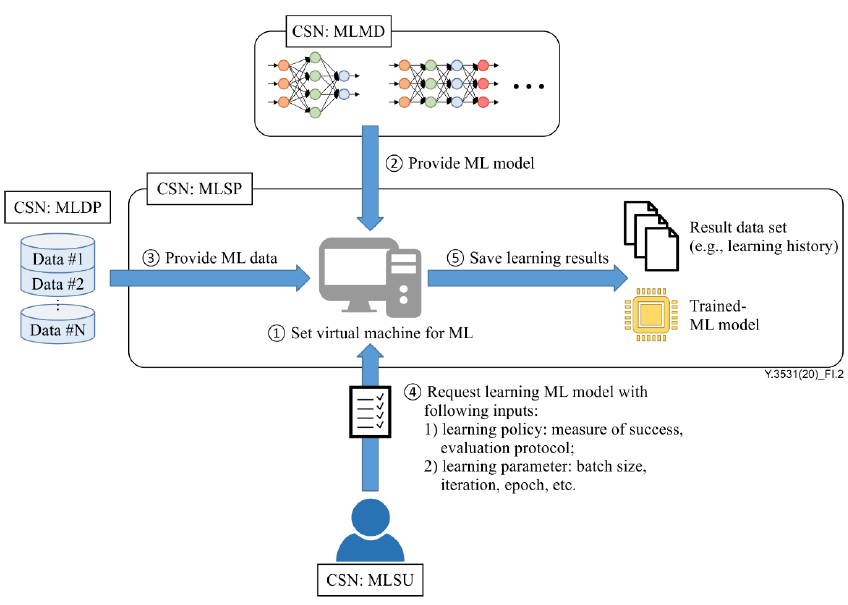 |
| 전제조건(선택) | CSC:MLSU는 CSP와 함께 가상 머신을 설치하여 ML 모델을 구축한다. CSP는 ML 모델을 구축하기 위한 ML 프레임워크 또는 플랫폼 도구를 제공한다. CSN:MLSU는 CSN:MLDP 및 CSN:MLMD에서 ML 데이터 및 모델을 검색하고 요청한다. |
| 사후조건(선택) | CSP:MLSP는 ML 결과 및 학습 진행 상황을 CSC:MLSU에 보고하기 위한 인터페이스를 제공한다. CSP:MLSP는 ML 애플리케이션 개발을 위해 훈련되거나 최적화된 ML 모델을 저장한다. |
4-3. 학습 결과 보고 및 ML 모델 재학습
<유즈 케이스: 학습 결과 보고 및 ML 모델 재학습>
| ?제목 | 학습 결과 보고 및 ML 모델 재학습 |
| 설명 | 이 사용 사례에서는 CSP:MLSP에서 CSC:MLSU로 학습 결과를 보고하고 ML 모델을 재학습하는 방법을 설명한다. 학습 결과 보고의 목적은 일반적으로 CSC:MLSU에 대한 ML 학습 구성 처리 및 관리에 대한 정보를 제공하는 것이다. CSC:MLSU는 ML 학습 매개변수를 최적화하고 ML 학습 정책을 수동으로 수정할 수 있다. 또한 CSC:MLSU는 재학습 옵션을 요청할 수 있다. 다음은 이 사용 사례에 대한 일반적인 단계이다. 1) CSC:MLSU는 CSP:MLSP에 학습 보고서를 요청한다. 2) CSP:MLSP는 적절한 인터페이스에서 학습 보고서를 변환하고 시각화한다. ※ 참고 1 - 시각화 옵션은 CSP:MLSP에서 CSC:MLSU로 제공될 수 있다. 훈련 결과의 원시 데이터가 기본 옵션이다. 3) CSP:MLSP는 학습 결과를 CSC:MLSU에 보고한다. 4) CSC:MLSU는 학습 보고서를 분석하고 학습 정책을 관리 및 최적화한다. ※ 참고 2 - 재설정 및 재훈련 단계는 '사용자 구성을 사용한 모델 훈련' 사용 사례(I.2절)의 단계와 동일한다. |
| 역할/하위역할 | CSP:MLSP CSC:MLSU |
| 그림(선택) | 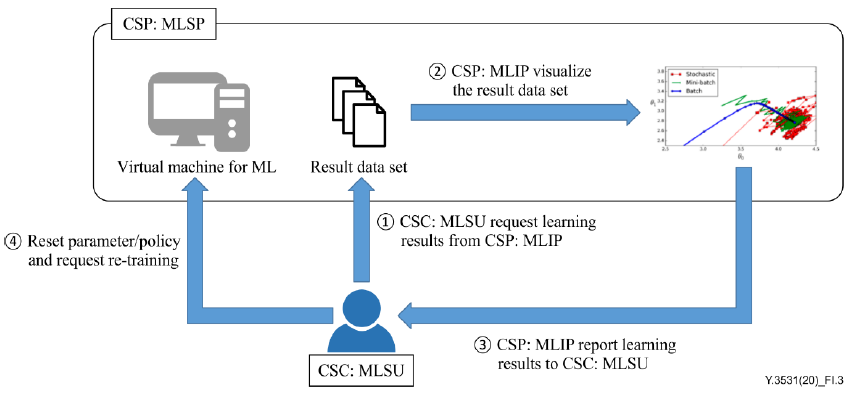 |
| 전제조건(선택) | CSN:MLSP는 이미 ML 학습을 수행하고 ML 모델에 대한 백업 결과 데이터를 저장한다. |
| 사후조건(선택) |
참 고 문 헌
- ITU-T Y.3531 (2020) Cloud computing ? Functional requirements for machine learning as a service
- ITU-T Y.3600 (2015) Big data ? Cloud computing based requirements and capabilities
- ITU-T Y.3502 (2014) Information technology ? Cloud computing ? Reference architecture
- ITU-T X.1601 (2015) Security framework for cloud computing
저작권 정책
K-ICT 클라우드혁신센터의 저작물인 『국제표준문서에서 MLaaS(Machine Learning as a Service)를 위한 기능 요구사항』은 K-ICT 클라우드혁신센터에서 상명대학교 서광규 교수에게 집필 자문을 받아 발행한 전문정보 브리프로, K-ICT 클라우드혁신센터의 저작권정책에 따라 이용할 수 있습니다.
다만 사진, 이미지, 인용자료 등 제3자에게 저작권이 있는 경우 원저작권자가 정한 바에 따릅니다.